
What are and How to use CSS Selectors for Web Scraping

Introduction
In the modern era of technology, information has become a valuable commodity. As a result, web scraping has grown in popularity as a means of gathering data from the internet. CSS selectors are among the most effective methods of extracting data from websites.
CSS selectors are codes that let you target specific HTML elements on a webpage and extract desired data. By using CSS selectors, you can avoid the need for intricate code and instead focus on the exact elements you want to extract.
This tutorial will introduce the fundamentals of CSS selectors and how to employ them for web scraping. You will discover the various types of CSS selectors and learn how to write CSS selector code to extract data from websites. Moreover, this tutorial will discuss some common problems that can occur when using CSS selectors for web scraping and how to troubleshoot them.
Whether you are new to web scraping or an experienced practitioner, this guide will equip you with the knowledge and resources necessary to use CSS selectors effectively for web scraping. So, let's get started and discover how to use CSS selectors for web scraping!
DOM and HTML elements
The Document Object Model (DOM) is a programming interface for HTML and XML documents. In simple terms, it's a tree-like structure that represents the elements on a webpage. Each element in the DOM tree corresponds to an HTML tag, and together they form the HTML structure of a webpage.
HTML elements, also known as HTML tags, are the building blocks of web pages. They define the content and structure of a webpage, such as headings, paragraphs, images, links, and more. HTML elements are written in code and surrounded by angle brackets, such as `<h1>` for a top-level heading, or `<p>` for a paragraph.
Here's an HTML code example that demonstrates the use of HTML elements and the DOM:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Welcome to my website</h1>
<p>
Here you will find all sorts of interesting content.
<a href="https://www.example.com">Visit Example.com</a>
</p>
<img src="example.jpg" alt="Example Image">
</body>
</html>
In this example, the `<html>` element is the top-level element, and all other elements are nested within it. The `<head>` element contains metadata about the document, such as the page's title, while the `<body>` element contains the page's visible content.
The `<h1>` element is a top-level heading, while the `<p>` element is a paragraph. The `<img>` element is an image, and the `<a>` element is a link to another webpage.
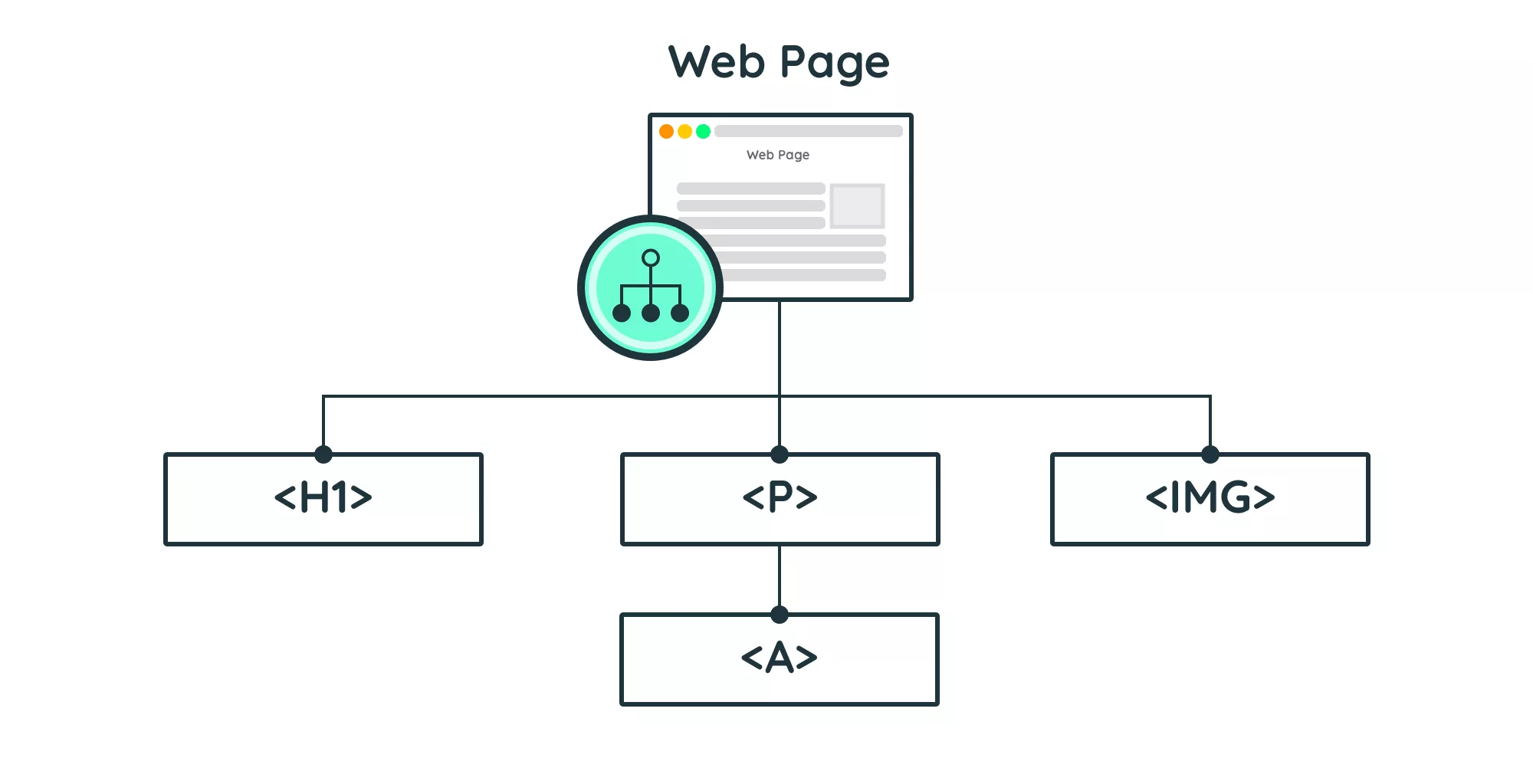
When a browser loads this HTML document, it creates a DOM tree that represents the elements on the page. The DOM tree is then used by the browser to render the page visually. By using CSS selectors, you can target specific elements in the DOM tree and extract the data you need for web scraping or other purposes.
What Is A CSS Selector?
CSS selectors are special codes that web developers can use to select specific HTML elements on a webpage and modify them.
For instance, CSS selectors can be used to change the color or layout of selected elements, such as altering the background color of all headings on a page.
In addition to styling, developers can use CSS selectors in combination with JavaScript to extract data from specific elements, such as gathering the text content of all hyperlinks on a page.
How CSS selectors work
To demonstrate how CSS selectors work, consider the scenario where you want to change the text color of all the paragraphs on a webpage. You could accomplish this task by using the following code:
p {
color: red;
}
In this code, `p` is the CSS selector that applies to all paragraph elements on the page. The curly braces `{}` hold the formatting rules, with the color property set to red, which changes the text color of all paragraphs to red.
How to select content using CSS selectors and JavaScript
For another example, suppose you want to collect the text content of all headings on a webpage using JavaScript. To achieve this goal, you would use the following code:
let headers = document.querySelectorAll('h1');
for (let i = 0; i < headers.length; i++) {
let headerText = headers[i].textContent;
console.log(headerText);
}
In this code, `document.querySelectorAll('h1')` is the CSS selector that applies to all `<h1>` elements on the page. The `querySelectorAll` method returns a list of all matching elements. The `for` loop iterates over the list and extracts the text content of each `<h1>` element using the `textContent` property. The collected text can then be processed further, such as by displaying it on the console.
How to test CSS selector code using JavaScript and a Browser
To try out the JavaScript code from the previous example, you can perform the following steps to open the Inspector tools in your web browser:
- Firstly, launch your web browser.
- Next, navigate to the web page where you want to test the code.
- After that, right-click on any section of the website, and from the menu that appears, choose "Inspect".
- A Developer Tools window will display. Click on the "Console" tab in the window.
- Copy and paste the JavaScript code into the console, and press the "Enter" key to execute it.
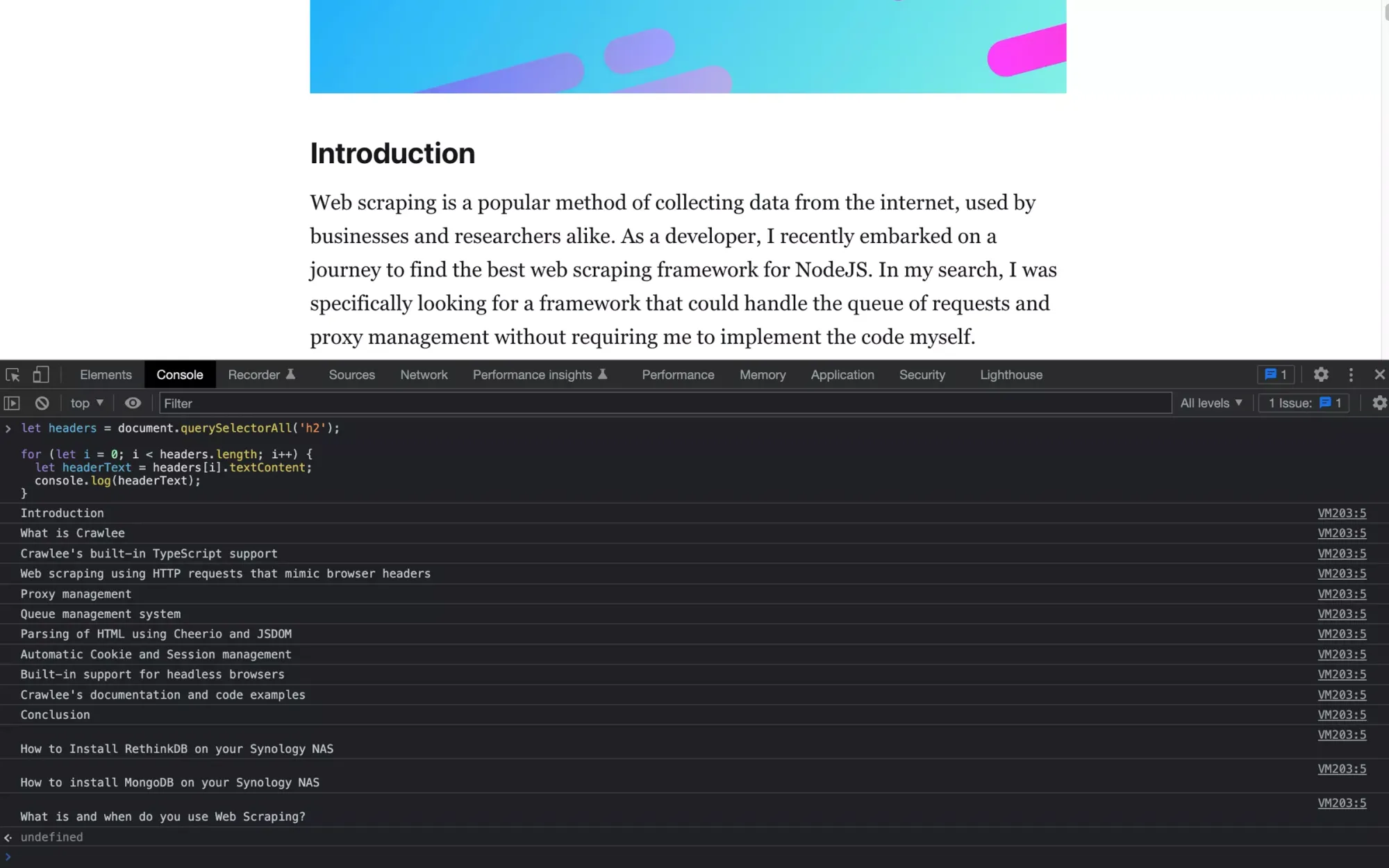
Once you run the code, the console will output the text content of all the `<h1>` elements on the page. You can then examine the output and verify that it is as expected.
Inspecting the HTML source code of a webpage using the Developer Tools in your web browser is an efficient way to debug and test JavaScript code that targets specific HTML elements. It enables you to test code interactively, view the output, and make modifications instantly, all within the same window.
More about the CSS selector syntax
In a previous section, we briefly talked about what a CSS selector is and how it works. Now, let's dive a little deeper into the CSS selector syntax and learn more about the different types of selectors that exist.
CSS selectors allow you to target a particular element on a webpage and apply styles or extract data from them. By understanding the different types of selectors and how to use them, you can become more efficient at styling and extracting data from web pages.
There are many types of CSS selectors, ranging from basic CSS selectors that target a single element to more advanced selectors that can target elements based on their attributes or position in the document hierarchy.
A CSS selector is made up of one or more elements, separated by whitespace, with the last one being the element that's actually selected. Using more than one element specifies a hierarchy that must be satisfied for the element to be selected.
For example, the selector `h1` selects all `<h1>` tags in the document, while the selector `article h1` selects only `<h1>` tags that are descendants of an `<article>` element. An `<h1>` tag that's a child of the `<body>` tag would not be selected by the `article h1` selector.
Here is a list of commonly used CSS selectors, along with their examples and descriptions, presented in a table format as a reference guide:
| Selector | Example | Description |
|---|---|---|
| Element Selector | h1 | Selects all instances of an HTML element |
| Attribute Selector | a[href] | Selects all instances of an HTML element that have a specific attribute |
| ID Selector | #my-id | Selects an element with a specific ID attribute |
| Class Selector | .my-class | Selects all elements with a specific class attribute |
| Descendant Selector | article h1 | Selects all instances of an HTML element that are descendants of another HTML element |
| Child Selector | ul > li | Selects all instances of an HTML element that are direct children of another HTML element |
| Adjacent Sibling Selector | h1 + p | Selects the first instance of an HTML element that comes immediately after another HTML element |
These are some of the most commonly used CSS selectors in web development. They allow developers to target specific elements on a webpage and style or manipulate them as desired.
You can find the full list here: https://www.w3schools.com/cssref/css_selectors.asp
Remember that you can always combine multiple CSS selectors to select elements on page.
The class attribute is your friend when scraping a web page
The attribute that's often used in HTML and selectors to identify content is referred to as the class attribute. This attribute is applied to a group of elements to define a class, which is frequently utilized by developers to style similar elements. It can also be useful in web scraping to extract specific data from a website.
By utilizing CSS class selectors, web scrapers can extract data from targeted elements on a webpage with ease. For instance, to extract product names and prices from an e-commerce website, web scrapers can inspect the HTML and identify that each product is contained in a div element with a "product" class. With the ".product" CSS selector, web scrapers can extract the product names and prices from all elements with the "product" class.
Conclusion
In conclusion, this guide provides a useful reference for some of the most commonly used CSS selectors, along with examples and descriptions that can help in the styling of web pages or the extraction of data from websites through web scraping.
If you're looking for web scraping libraries that support CSS selectors, I invite you to check out my articles "The Best Web Scraping Framework for NodeJS" which utilizes the Cheerio library, and "What is the Best Language for Web Scraping and Why?" which covers a variety of programming languages and libraries available for web scraping.
Using CSS selectors can greatly simplify web scraping and make it more efficient, allowing you to focus on the specific elements of a webpage that contain the data you need. With the knowledge of the most commonly used selectors presented in this guide, you can start applying CSS selectors to your web development or web scraping projects with ease.